$$ \newcommand{\pr}[1]{\mathbb{P}\left(#1\right)} \newcommand{\cpr}[2]{\mathbb{P}\left(#1\mid\,#2\right)} \newcommand{\expec}[1]{\mathbb{E}\left[#1\right]} \newcommand{\var}[1]{\text{Var}\left(#1\right)} \newcommand{\sd}[1]{\sigma\left(#1\right)} \newcommand{\cov}[1]{\text{Cov}\left(#1\right)} \newcommand{\cexpec}[2]{\mathbb{E}\left[#1 \vert#2 \right]} $$
7 Multiple random variables
7.1 Joint probability distributions
It is essential for most useful applications of probability to have a theory which can handle many random variables simultaneously. To start, we consider having two random variables. The theory for more than two random variables is an obvious extension of the bivariate case covered below.
Remember that, formally, random variables are simply mappings from \(\Omega\) into some set. A bivariate random variable is a mapping from \(\Omega\) into a Cartesian product of two sets, i.e., a random variable whose values are ordered pairs of the form \((x,y)\). Of course, a bivariate random variable is a random variable according to our original definition, just with a special kind of set of possible values. However, the concept of bivariate random variable is a useful one if the individual components of the bivariate variable have their own meaning or interest.
Here is a picture: 
Note that the set of possible values \((X,Y)(\Omega) = \{ ( X(\omega), Y(\omega) ) : \omega \in \Omega \}\) is a subset of the Cartesian product \(X(\Omega) \times Y(\Omega)\).
Similarly to before, for any \(A \subseteq X(\Omega)\times Y(\Omega)\), we write ‘\((X,Y) \in A\)’ to denote the event \[\{ \omega \in \Omega\colon (X(\omega),Y(\omega)) \in A \}.\] For any \(x\in X(\Omega)\) and \(y\in Y(\Omega)\), we write ‘\(X = x,Y=y\)’ to mean the event \((X,Y)\in\{(x,y)\}\). We sometimes also write \(\{(X,Y)=(x,y)\}\) and \(\{(X,Y)\in A\}\) to emphasize that these are sets: \[\begin{aligned} \{X = x,Y=y\} &:= \{(X,Y)\in\{(x,y)\}\} \\ &= \{X=x\}\cap\{Y=y\} \\ &= \{\omega \in \Omega\colon X(\omega) = x\text{ and }Y(\omega)=y\}.\end{aligned}\] We may also write more complex expressions like: \[\{0\le X\le Y^2\le 1\}= \{ \omega \in \Omega\colon 0\le X(\omega)\le Y(\omega)^2\le 1 \}.\]
Three random variables, \(X\), \(Y\), and \(Z\), say, are independent if the events \(\{ X \in A \}\), \(\{ Y \in B\}\), \(\{ Z \in C \}\) are mutually independent. Similarly for any finite collection of random variables. This definition is a bit unwieldy: it reduces to simpler statements in the cases of pairs of discrete or continuous random variables, which we look at next.
7.2 Jointly distributed discrete random variables
Note there is nothing really new here, other than the terminology: this is just the definition of a discrete random variable written for the special case of a random variable \((X,Y)\) whose values are ordered pairs of the form \((x,y)\).
To avoid ambiguity, we sometimes write if \(p_{X,Y}(\cdot)\) if it is not clear from the context which random variables the two arguments refer to; note that \(p_{X,Y}(\cdot)\) is not the same as \(p_{Y,X}(\cdot)\).
It is the case that \((X,Y)\) is discrete if and only if the individual random variables \(X\) and \(Y\) are discrete. Proving this is the purpose of the following theorem, which and also explains how the marginal probability mass functions \(p(x)\) and \(p(y)\) of the individual random variables \(X\) and \(Y\) are connected to the joint probability mass function \(p(x,y)\). Note that it does no harm to take \(\mathcal{Z} = \mathcal{X} \times \mathcal{Y}\), extending the definition of \(p(x,y)\) with extra \(0\) values if necessary.
Again, by C7, the joint probability mass function determines the joint probability distribution of \(X\) and \(Y\), and the values of the joint probability mass function sum to one:
This isn’t really a new idea: it is just the result about probability mass functions from Section 6.2 rewritten for the case of a discrete random variable whose possible values are ordered pairs \((x,y)\).
Often we want to know the distribution of one random variable conditional on the value of another random variable.
There’s nothing new here, apart from the notation: this is just a particular case of the usual definition of conditional probability of one event given another, e.g., \[\cpr{X=x}{Y=y}=\frac{\pr{X=x, Y=y }}{\pr{Y=y}} = \frac{p_{X,Y}(x,y)}{p_Y(y)}.\]
There is also a version of P4 (partition theorem or, law of total probability) for discrete random variables; again, only the notation is new here.
A version of the above result also holds with \(X\) and \(Y\) swapped.
Recall from the definition of independence of random variables that \(X\) and \(Y\) are independent random variables if events \(\{ X \in A \}\) and \(\{ Y \in B \}\) are independent for all \(A, B\). If \(X\) and \(Y\) are discrete, the following result gives a simpler characterization of independence.
It follows that for independent discrete random variables \(X\) and \(Y\), \(p_{X \vert Y}(x,y)=p_X(x)\) whenever \(p_Y(y)>0\), and \(p_{Y \vert X}(y,x)=p_Y(y)\) whenever \(p_X(x)>0\).
7.3 Jointly continuously distributed random variables
To avoid ambiguity we sometimes write \(f_{X,Y}(x,y)\) for the joint probability density of \(X\) and \(Y\). The interpretation of \(f(x,y)\) is that \[\pr{X\in [x,x+ \, d x], Y\in [y,y+ \, d y]}=f(x,y) \, d x \, d y \tag{7.2}\] for \(x,y\) at which \(f(x,y)\) is continuous.
As before, the joint probability density function \(f(x,y)\) determines the joint probability \(\pr{(X,Y)\in A}\) for most events \(A\). More precisely, remember the definition of type I and II regions in the theory of multiple integration: a type I region is of the form \[D=\{a_0\leq x\leq a_1,\ \phi_1(x)\leq y \leq\phi_2(x)\}\] for some continuous functions \(\phi_1\) and \(\phi_2\), and a type II region is of the form \[D=\{\psi_1(y)\leq x\leq\psi_2(y),\ b_0\leq y\leq b_1\}\] for some continuous functions \(\psi_1\) and \(\psi_2\).
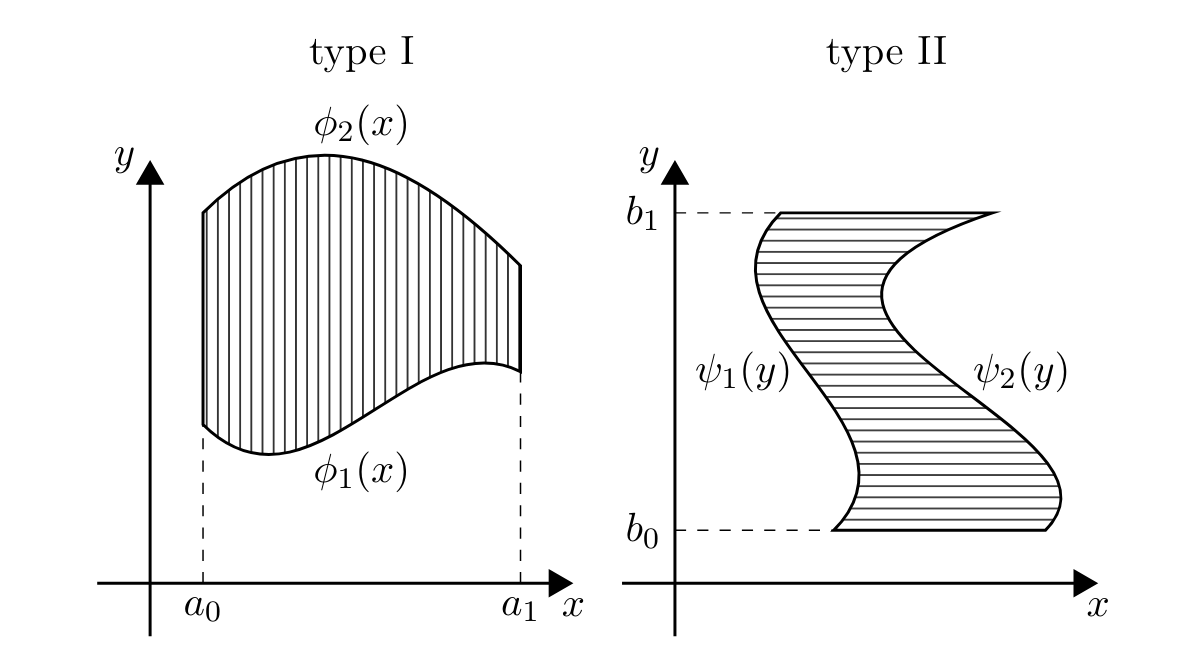
As we know from calculus, unions of regions of these types are precisely the regions over which we can integrate1. So, we have:
Again as before, \(f(x,y)\) integrates to one:
Note that, if \(X\) and \(Y\) are jointly continuously distributed, then for any interval \([a,b]\), \[\pr{X\in [a,b]} = \pr{X\in [a,b], Y\in\mathbb{R}} = \int_a^b\left(\int_{-\infty}^\infty f(x,y) \, d y \right) \, d x,\] so, by the definition of a continuous random variable, \(X\) is continuously distributed as well, as is \(Y\) by a similar argument. We have shown the following:
In a multivariate context, the probability density functions \(f_X(x)\) and \(f_Y(y)\) are also called marginal probability density functions.
Similarly to the discrete case, independence can be characterized as a factorization property of the joint probability density function.
For independent jointly continuously distributed \(X\) and \(Y\), \(f_{X\vert Y}(x \vert y)=f_X(x)\) whenever \(f_Y(y)>0\), and \(f_{Y\vert X}(y \vert x)=f_Y(y)\) whenever \(f_X(x)>0\).
7.4 Functions of multiple random variables
Suppose \(X:\Omega\to X(\Omega)\) and \(Y:\Omega\to Y(\Omega)\) are (discrete or continuous) random variables, and \(g: X(\Omega)\times Y(\Omega)\to\mathcal{S}\) is some function assigning a value \(g(x,y) \in \mathcal{S}\) to each point \((x,y)\). Then \(g(X,Y)\) is also a random variable, namely the outcome to a ‘new experiment’ obtained by running the ‘old experiments’ to produce values \(x\) for \(X\) and \(y\) for \(Y\), and then evaluating \(g(x,y)\).
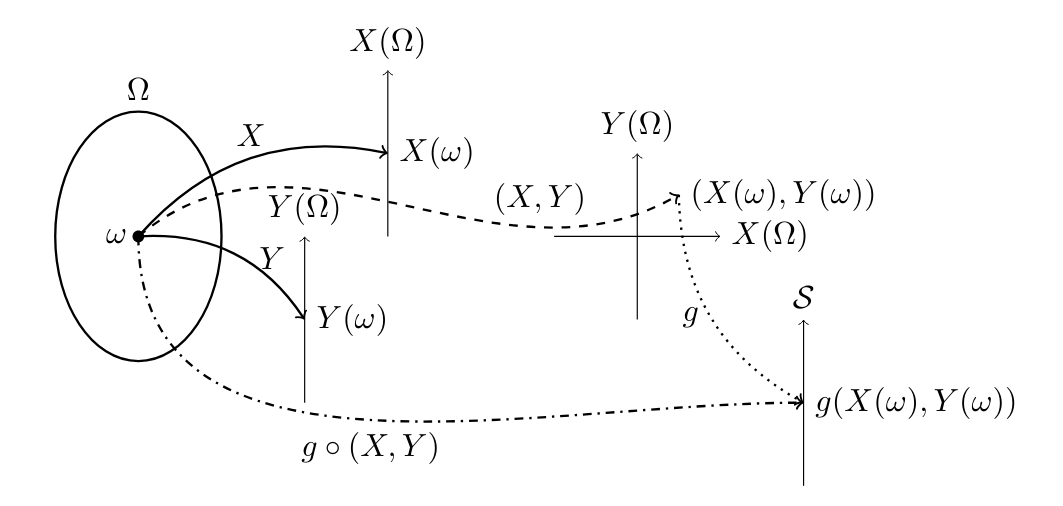
Formally, \(g(X,Y):= g\circ (X,Y)\), or in more specific terms, the random variable \(g(X,Y):\Omega\to\mathcal{S}\) is defined by: \[g(X,Y)(\omega):= g(X(\omega),Y(\omega))\text{ for all }\omega\in\Omega.\] For example: \[\pr{ g(X,Y)\in A } = \pr{ \{\omega\in\Omega: g(X(\omega),Y(\omega))\in A\} } \text{ for all } A\subseteq\mathcal{S}.\]
For any random variables \(X\) and \(Y\), \(X+Y\), \(X - Y\), \(XY\), \(\min(X, Y)\), \(e^{t(X + Y)}\), and so on, are all random variables as well.
At least when restricted to the Riemann integral.↩︎